python
-

python如何实现百度贴吧自动回复
要想实现贴吧自动回复,首先要保证已经登录了,针对这个问题,我最开始想的办法是通过cookies解决,但是实操后发现不行。既然通过cookies直接登录贴吧不行,那我就先用cookies登录百度首页,然后在进贴吧,这种做法也失败了。最后我就再次做了一下尝试,直接使用账号与密码实现自动登录,再进入贴吧,实测后发现能用。但是,若想实现完全自动登录,这里是有个问题的,那就是因为登录需要手机验证,手机验证码是我们无法自动获取的。那怎么办呢,详情代码可以关注下面公众号,回复贴吧自动回复,查看完整代码。 ...
-
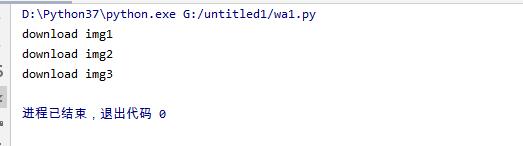
python如何下载图片到本地?
import os from urllib.request import urlretrieve import requests os.makedirs('./image/', exist_ok=True) IMAGE_URL = "http://shenhuwei.com/zb_users/upload/2020/12/ ...
-
python百度自动登录代码
from selenium import webdriver import time baiduuser = input('百度账号:') baidupassword = input('百度账号密码:') emailuser = input('邮箱账号:') emailpassword = input('邮箱 ...
-

xlrd如何读取excle表中的内容
import xlrd# 打开文件wb = xlrd.open_workbook(filename='百度账号.xls')#获取所有表的名称print(wb.sheet_names())['Sheet1', 'Sheet2', 'Sheet3']#获取sheet数量print(wb.nsheets)3#获取所有的sheet数量print(wb.sheets())[<xlrd.sheet.Sheet object at 0x00 ...
-

python如何获取一次获取26个英文字母
第一种方法,也是最笨的方法,自己输入。第二种方法,使用string方法string.ascii_uppercase,26大写英文字母string.ascii_lowercase,26个小写英文字母第三种方法,使用字ord函数ord() 函数是 chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值,如果所给的 Unicode 字符超出了你的 P ...
-
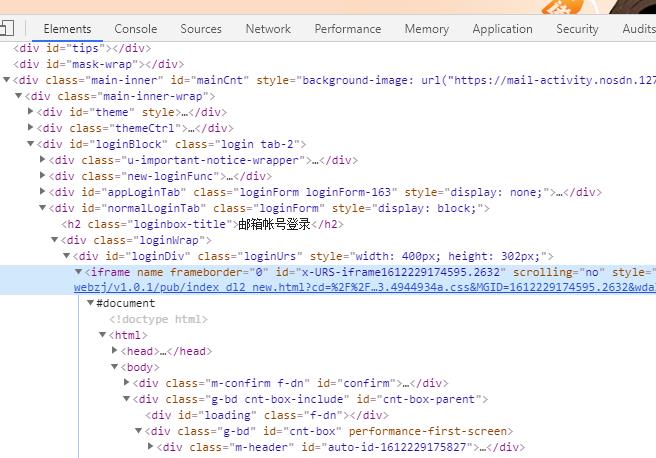
如何使用selenium自动登录网易邮箱,及xpath中stars-with与ends-with的用法介绍
网易邮箱在使用selenium实现自动登录的时候,有一点是需要我们注意的,如果没有注意到这个点,那么就是没有办法实现自动登录的。这个需要关注的点就是iframe窗口,其实通过审查元素仔细看你会发现,网易邮箱这个登录界面的html中有一个iframe,iframe下又有一个<html>,这其实就是说,在当前页面有个新的窗口,窗口中有个html。所以,要想查找到登录的元素,我们必须要将窗口切换到iframe中。具体代码如下:from selenium import&n ...
-
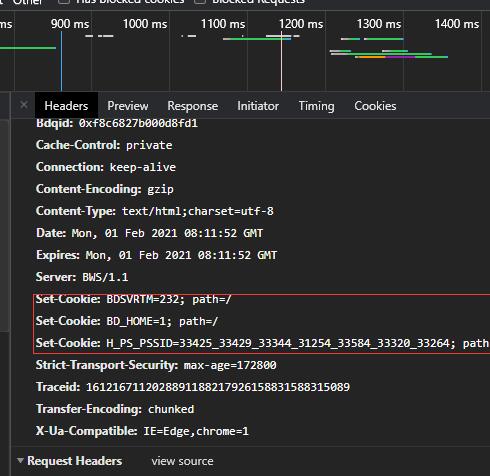
selenium如何获取cookies,并实现使用cookies自动登录(一)
最近在研究一个新的知识,遇到了一个困难,就是selenium获取并使用cookies的技巧。刚开始百度了下,看了一些介绍,始终是不明白怎么回事,因为网上大部分是这样介绍的:一、cookies的获取1、手动获取网上大部分都说是看上图,但是这就让我看不懂了啊,因为百度出来的selenium中cookies添加是这样的一种格式:cookies=[{'domain': 'zhuxiaoedu.com', 'expiry': 1643699649, ' ...
-
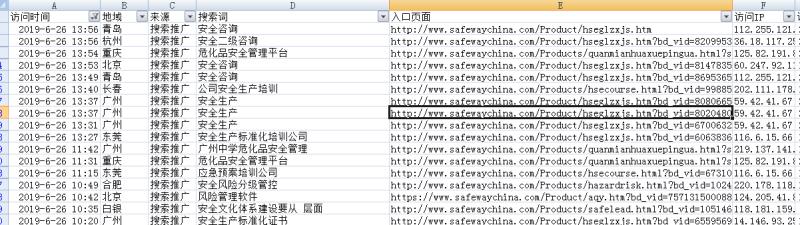
python如何实现抓取一个网站的所有页面URL,并且检查网站是否有404页面工具
之前有研究过爬取一个网站中所有网页的URL脚步,后来再去用的时候发现是错误的,所以就想着再写一个。刚开始想来想去想不到办法,因为要抓取网站下所有页面的URL需要使用到递归,而python中递归使用次数是有限制的,超过了就会跑错。于是百度一下看看有没有解决的办,搜来搜去就发现了以下的这段代码:import requestsfrom bs4 import BeautifulSoup as Bs4 head_url =&nbs ...
-

python列表中del与remove用法详细介绍
今天在抓取数据的时候,遇到一个问题困扰了我好久,后来发现原来是基础不牢引发的bug。下面我就给大家分享一下,关于列表中的del与remove用法深究。看代码
strlist11=['1','2','3','@','@','4','5','6','#','7','8','9','%','10','11','12','$','13','14'] strlist1=['1','2','3','@','4','5','6','#','7','8','9','%','10','11','12','$','13','14'] strlist2=['1','2','3','@','4','5','6','#','7','8','9','%','10','11','12','$','13','14'] strlist4=['1','2','3','@','@','4','5','6','#','7','8','9','%','10','11','12','$','13','14'] strlist3=['1','2','3','@','@','4','5','6','#','7','8','9','%','10','11','12','$','13','14'] shanchu=['@','#','%','$'] i=0 for str in strlist1: for shan in shanchu: if shan==str: del strlist1[i] break i+=1 # strlist1中要被删除元素不在一起 m=0 for str in strlist11: for shan in shanchu: # 在这里我们打印一下strlist11[m]与strlist3[m] print('strlist3[%d]:%s===strlist11[%d]:%s'%(m,strlist3[m],m,strlist11[m])) if shan==str: del strlist11[m] break m+=1 print('*' * 10) #strlist11中要被删除元素在一起 for str in strlist2: for shan in shanchu: if shan==str: strlist2.remove(str) break # strlist2中要被删除元素不在一起 n=0 for str in strlist4: # 在这里我们打印一下strlist11[n]与strlist3[n] print('strlist3[%d]:%s===strlist4[%d]:%s' % (n,strlist3[n],n, strlist4[n])) for shan in shanchu: if shan==str: strlist4.remove(str) break n+=1 print('*'*10) # strlist4中要被删除元素在一起 print('# strlist1中要被删除元素不在一起') print(strlist1) print('# strlist11中要被删除元素在一起') print(strlist11) print('# strlist2中要被删除元素不在一起') print(strlist2) print('# strlist4中要被删除元素在一起') print(strlist4)... -
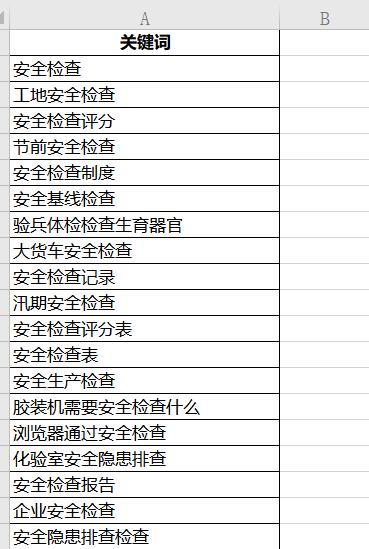
关键词快速分词工具Python版
我这里已经有了一个关键词分词工具excle版的,但是需要激活后的office才能使用,或者购买wps会员版才能用。于是我就用Python写了一个,使用起来非常方便,这里给大家介绍下如何使用。
一、打开guanjianci.xls,将需要分词的关键词复制到表格第一列,保存。记住不要覆盖原有的第一行,第一行是固定的关键词,方便让大家知道将关键词放在哪里。
...