python
-

python随机启动浏览器,并实现关键词搜索与查找功能代码
import time import random from selenium import webdriver a=random.randint(1,3) if a==1: browser = webdriver.Chrome() elif a==2: browser=webdriver.Fi ...
-

selenium使用google如何使用代理IP
selenium可以模拟浏览器进行点击,但是如果同一IP操作过多,就会出现排斥,从而抓取不到数据。所以,学会使用代理IP是使用selenium的重要一个知识点,下面我就来给大家分享下如何使用代理IP启动google浏览器。下面是代码:from selenium import webdriver from selenium.webdriver import ChromeOptions import time import& ...
-

如何使用python自动搜索,并点击搜索结果
这里是简单版本的自动搜索,并点击,我们只需要输入自己想要搜索的关键词,然后就会自动打开百度搜索,并且将结果一个一个点开,并关闭,这里因为是展示,只设置了搜索第一页,下面是完整代码:import time from selenium import webdriver guanjianci=input('请输入关键词:') browser = webdriver.Firefox() browser.get(' ...
-

如何用python抓取爱企查企业信息
前段时间,经理让我去找一些企业的信息,我平常习惯于使用爱企查。所以,便想着写一个程序来实现这个,所以有以下的代码:import json import requests import re from lxml import etree url="https://aiqicha.baidu.com/s?q="+公司名称+"=0" headers={"User-Agent" ...
-

python如何无界面启动google浏览器模拟点击操作
python可以通过selenium模拟启动google浏览器进行点击操作,但是虽然不用自己操作了,却还是会暂用电脑,毕竟很多人都只有一台电脑,这样还是不能够提高工作效率。下面小编就来介绍下selenium启动google的另一个技巧,及无界面启动google浏览器,这样在模拟启动的时候电脑上是不会出现google浏览器的,我们在运行程序的时候就可以正常的做其他工作了,大大提高了工作效率,下面是完整代码与每句代码的介绍,其中options.add_argument('--headless ...
-

python关键词排名查询代码
python写的关键词精准排名查询工具,有需要可以看看 headers={'User-Agent':' Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904. ...
-
python实现自动登录百度账号功能代码
from selenium import webdriver import time driver = webdriver.Chrome() driver.implicitly_wait(10) driver.get("http://www.baidu.com") driver.find_element_by_link_text('登录').click() time.sleep ...
-
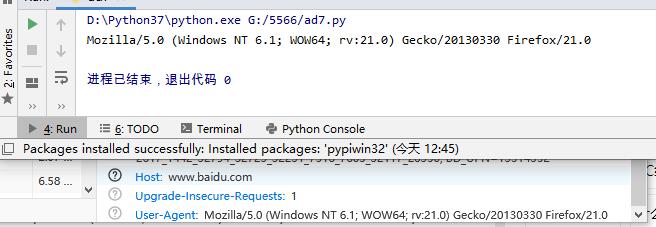
python selenium火狐浏览器如何设置请求头
火狐浏览器设置请求头的具体方法如下:from selenium.webdriver.firefox.firefox_profile import FirefoxProfile from selenium import webdriver from fake_useragent import UserAgent import time option=FirefoxProfile() u ...
-
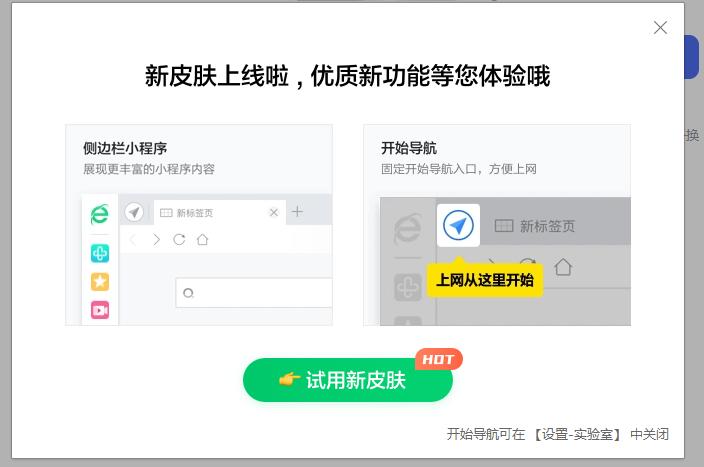
python selenium使用360浏览器出现新皮肤设置怎么办?
小编最近在学selenium,在模拟使用360浏览器发现一个问题,就是每次打开后,都会出现皮肤设置选项。刚开始搞不清楚是什么原因,仔细想了一下才发现,这不就是第一次安装360浏览器,第一次使用的时候出现的情况吗。于是我在代码中加了一句这样的代码chrome_options.add_argument(r"user-data-dir=C:\Users\Administrator\AppData\Local\360Chrome\Chrome\User Data"),也就是 ...
-
如何python抓取网站新闻目录下面的所有子分类及内容?
import requests from bs4 import BeautifulSoup import time chushiurl="http://www.**.cc/seojs/" headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64)& ...