python
-
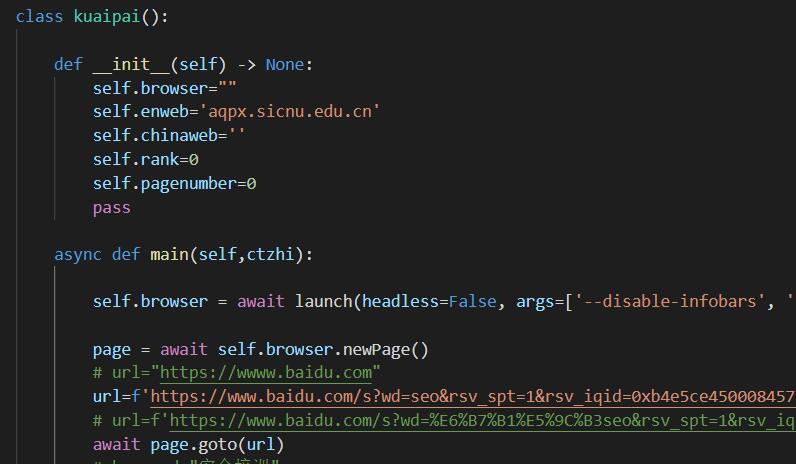
pyppeteer使用教程,入门到精通
Puppeteer 是 Google 基于 Node.js 开发的一个工具,有了它我们可以通过 JavaScript 来控制 Chrome 浏览器的一些操作,当然也可以用作网络爬虫上,其 API 极其完善,功能非常强大。 而 Pyppeteer 又是什么呢?它实际上是 Puppeteer 的 Python 版本的实现,但他不是 Google 开发的,是一位来自于日本的工程师依据 Puppeteer 的一些功能开发出来的非官方版本。
Pyppeteer 就是依赖于 Chromium 这个浏览器来运行的。那么有了 Pyppeteer 之后,我们就可以免去那些繁琐的环境配置等问题。如果第一次运行的时候,Chromium 浏览器没有安装,那么程序会帮我们自动安装和配置,就免去了繁琐的环境配置等工作。另外 Pyppeteer 是基于 Python 的新特性 async 实现的,所以它的一些执行也支持异步操作,效率相对于 Selenium 来说也提高了。
... -

使用python useragent ,提示错误ModuleNotFoundError: No module named 'fake_useragent'如何解决
使用from fake_useragent import UserAgent,在运行程序的时候提示ModuleNotFoundError: No module named 'fake_useragent',于是使用pip命令安装了
UserAent库,再次运行,发现还是提示错误。
... -
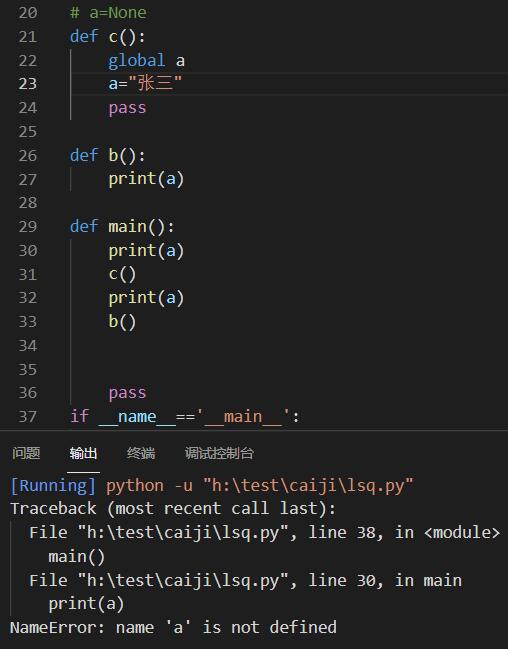
python中使用global并不一定要在头部申明变量名
对于global的用法,我一直以为是一定要在头部进行申明变量名,后面才能操作,比如说这样:
a=None def c(): global a a="张三" pass def b(): print(a) def main(): print(a) c() print(a) b() pass if __name__=='__main__': main()
... -
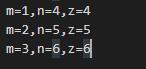
python中zip()函数及zip在for循环中使用的详细介绍
描述
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存。
我们可以使用 list() 转换来输出列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
a = [1,2,3]
b = [4,5,6]
... -
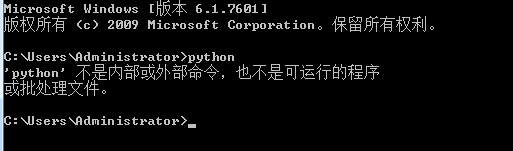
windows 7系统如何设置Python的环境变量
Python安装好后,想要运行还得设置好环境变量才可以,下面就给大家介绍下windows 7系统下,如何设置Python环境。
在没有设置环境的时候,我们在cmd下输入python运行,提示“'python' 不是内部或外部命令,也不是可运行的程序或批处理文件。”
... -
python往phpmyadmin里插入数据,中文字符呈现乱码的原因
今天想采集一些数据存入到数据库中,留着以后使用。可是当我打开phpmyadmin新建好数据库与数据表之后,再使用python往里面插入数据时,发现中文字符全部乱码。因为之前已经有过采集数据存储到phpmyadmin的操作,所以直接换了个数据库试试,结果发现依然是这样。
... -

使用随机UserAgent报错Error occurred during loading data. Trying to use cache server https://fake-useragent
今天在使用随机请求头运行程序后报错了,我的代码是这样的:ua = UserAgent() useragent=ua.firefox headers={'user-agent':useragent}报错信息是这样的:Error occurred during loading data. Trying to use cache server https://fa ...
-

python如何一次替换字符串中所有的中文标点符号及英文标点符号
替换英文标点符号from string import punctuation print(punctuation) str1='我,是.中…国…人 —我—爱"祖国"和人民!;' for a in punctuation: str1=str1.replace(a,'') print(str1)替换中文标点符号 ...
-

python如何写一个zblog采集程序
最近写了一段代码,实现了采集文章后自动上传到博客的脚步,之前也想过要搞一个,当时思路是通过数据库,将采集的内容更新到数据库里。当然,这样是可以实现的。之后又有了一个思路,就是避开数据库,直接后台操作。搞了一段时间,一直找不到一个重要的参数,最近几天终于找到了,于是就有了以下的一段代码,现在分享出来: import requests import json from hashlib import md5 from bs4 ...
-

python如何实现抓去李毅吧热门贴图片
李毅吧是一个比较大的百度贴吧了,里面的热门内容都是非常好的内容。所以,我就写了一个实现抓去里面热门帖子图片的脚步,现在分享出来给大家,希望大家一起进步学习:import requests from lxml import etree from bs4 import BeautifulSoup import threading import time import os import&n ...